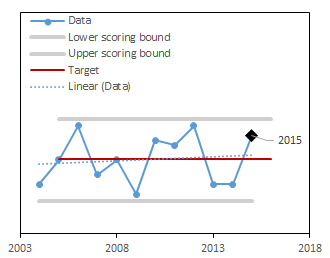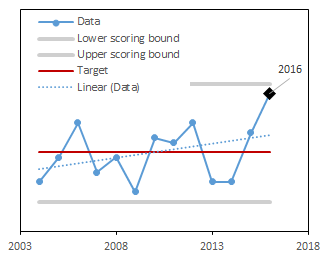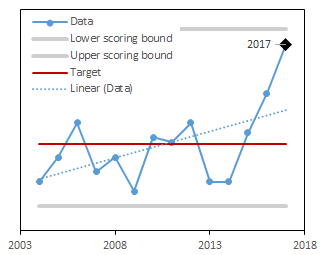
The size, density, diversity and arrangement of trees in the forest, and the pattern of that forest on the landscape.

trend is
flat
over time
Forest cover is the percent of the state of Vermont with tree cover.

trend is
down
over time
Regeneration of sugar maple seedlings provides information about the future of Vermont's hardwood forests.
trend is
flat
over time
Regeneration of red spruce seedlings provides information about the future of Vermont's softwood forests.

trend is
up
over time
Forests with greater stand complexity have trees in a range of sizes and as a result, may be more productive and resilient to stress.
trend is
flat
over time
Forest patch sizes provides information on the average size of contiguous forest blocks.
trend is
flat
over time
Forest connectivity is a measure of the linkages among Vermont's forests.
trend is
down
over time
With greater diversity in tree species, forests can support more biodiversity, exhibit higher resilience to stress, and store more carbon.
trend is
down
over time
Across the landscape, having a range of forest stand ages provides diversity, varied habitat conditions, and resilience to stressors.
The overall health of the trees within the forest and the lushness of the forest canopy across the landscape.
trend is
down
over time
The average crown dieback of trees in Vermont's forest provides us information on overall forest health.
trend is
flat
over time
Damages to forests occur from insects, diseases, weather events, animals, and human impacts.
trend is
flat
over time
Forest growth provides information on how much biomass Vermont's trees add annually.
trend is
flat
over time
Higher values of canopy density indicate a more lush, green, and productive forest.
trend is
flat
over time
Mapped forest mortality is an assessment of the total area of current-year tree mortality across the landscape.
trend is
flat
over time
The proportion of trees with damage and decay provides information on the condition and the potential timber quality of Vermont's trees.
trend is
flat
over time
Individual tree mortality is a natural and common event, but changes to the baseline rate can signify worsening environmental conditions for trees.
Stress agents acting on forests, impacting growth, regeneration and survivorship.
trend is
up
over time
Acid rain harms forests and other ecosystems by damaging leaves and leaching nutrients.
trend is
flat
over time
The length of the growing season varies from year to year, but large or persistent changes can be problematic to forests.
trend is
up
over time
Ozone can cause many negative impacts to forests by reducing regeneration, productivity, and species diversity.
trend is
flat
over time
Mercury is a toxin that persists in the environment for long periods by cycling back and forth between the air, water, soil and organisms - resulting in long-term, negative effects to forest ecosystems.
trend is
flat
over time
Warmer winter minimum temperatures can allow for non-native species to proliferate, while at the same time stressing native forest trees.
trend is
flat
over time
Higher maximum summer temperatures can stress forests, reducing productivity and health.
trend is
flat
over time
Changes to precipitation can alter the water balance in Vermont’s forests, causing either drought or deluge.
trend is
flat
over time
Snow insulates the soil and tree roots from cold temperatures and provides water when it melts.
trend is
flat
over time
Climate change will continue to result in more extreme weather events, which can stress forests beyond what they are accustomed.
trend is
flat
over time
Lack of sufficient precipitation can cause both immediate and long-term stress to trees.
trend is
flat
over time
As native trees are not adapted to defending themselves from non-native, invasive insects and diseases, widespread damage and mortality can result.
The many economic, social, ecological, and aesthetic services forests provide.
trend is
flat
over time
Timber harvested from Vermont's forests provide jobs and income to the state, and support the maintenance of forest land.
trend is
up
over time
Aquatic species that live in forested streams provide an assessment of the health of the surrounding forest.
trend is
up
over time
The ability of forests to support big game species for hunting indicates healthy forest habitat.
trend is
up
over time
The amount of carbon stored by forests helps offset rising atmospheric carbon dioxide concentrations.
trend is
up
over time
Maple syrup production is an iconic staple of Vermont's landscape and is reliant on the continued health of maple trees.
trend is
flat
over time
The number of people using Vermont's forests for camping and hiking provides a measure of the value of our forests for recreational uses.
trend is
down
over time
The number and diversity of bird species that live and use forested habitats provides a sense of the quality of Vermont's forestlands for a variety of species.